一起来撸printf吧
printf实现还隐藏了很多参数,例如%n,printf返回值是啥你知道吗?格式化字符串漏洞成因何在?这里分析Linux内核中的printf实现,而非glibc库中的标准实现(我们用的肯定是标准库咯,不过很复杂~_~),因为这里没有%f等浮点类型的匹配,简单一些.
参考资料:
Linus的github仓库https://github.com/torvalds/linux/blob/master/arch/x86/boot/printf.c
printf大体
首先我们找到printf函数的实现(由于x86体系容易理解便选择了这个体系),可以看到申请了1024个字节的空间来保存要格式化串,有人会问要是我给出的参数超过了1024不就缓冲区溢出程序会crash掉吗?我觉得编译器肯定会察觉到的,有兴趣的自己鼓捣下…大体就是将传递进来的参数根据压栈的顺序逐个取出并格式化成字符串,这个是在vsprintf函数实现的,返回值是两个地址的差,即本次输出的字符串数目.最后调用puts函数向终端输出.最后后才返回本次输出字符串数目.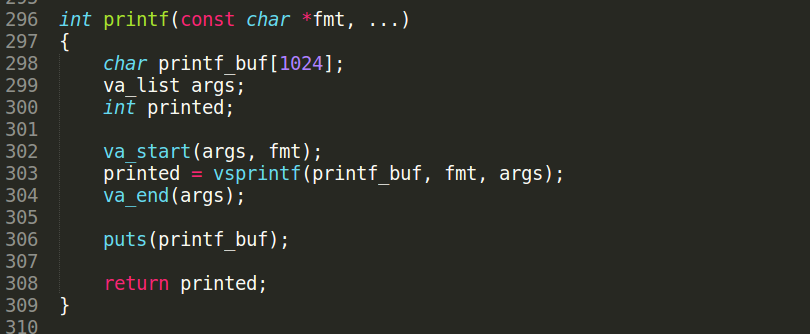
va_系类宏
然后我们利用sublime的插件来jump到va_list的定义,发现是一个char*的typedef.干脆就一起来认识一下va_系列的宏.
acpi_native_int也是一个typedef,根据最开始的配置决定是s32还是s64,在x86这里肯定就是有符号的32位了,即int类型的._AUPBND和_ADNBND两个宏的值一样.而_bnd这个宏在32b体系下给出的是类型X的大小的4字节对齐值.在printf里面用的时候关系不是很大,因为格式化的时候不会是很大结构体(%结构体根本没实现啊),纵然是小于4字节的char,short之类的,存的时候可能是那么多字节,但是压栈的时候编译器会毫不犹豫地安排用一个寄存器扩展并压入栈顶的指令,所以不用担心,可以认为这个宏在printf里面仅仅是4字节对齐没问题的.va_start(ap, A)这个宏接到A(fmt)地址,再+4赋值给ap,原因在于A(fmt)是printf的第一个参数(格式化字符串含有%的部分),+4之后才能对准第一个真正要格式化的参数.而va_arg(ap, T)目的是先使得ap移往后一个参数但是返回的值确实本次参数的值,比较巧妙.va_end(ap)仅仅为了保证安全而象征性地将ap指向NULL.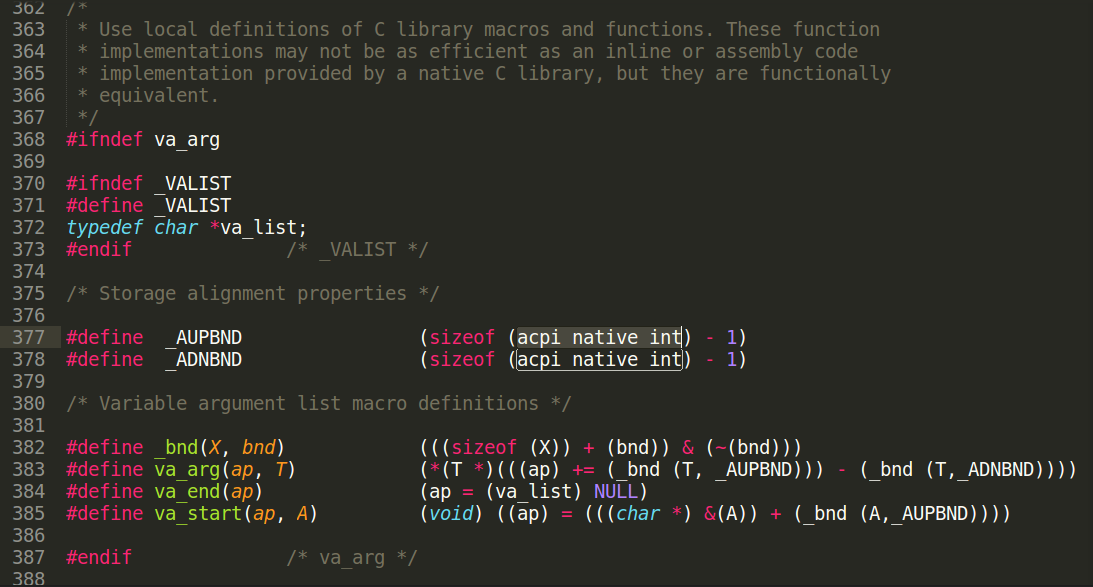
vsprintf
vsprintf这个函数有几个重要的局部变量需要注意,英文注释写的很清楚了,flags标志主要是关于数字对齐这一块,等到number函数被调用的时候会判断的.field_width字段主要是占用宽度计算.precision是精度计算,其实是输出个字符个数控制.qualifier是对于长整型的扩展,例如将int转为long.(x86下int=long)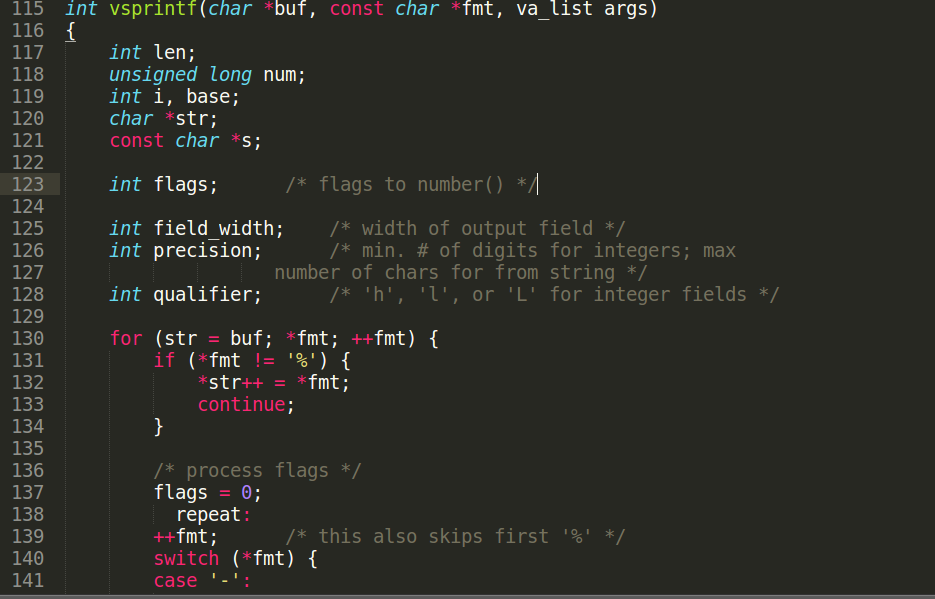
在定义了局部变量之后,一个for循环遍历fmt所有的字符,取出特别的%来格式化,最后计算地址偏移便完结了.当找到第一个%的时候,首先处理flags字段,定义个标号repeat来快速跳出,虽然听说C标准不推荐使用goto语句,但是能够提高效率为什么不能用呢?代码片段如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/* process flags */
flags = 0;
repeat:
++fmt; /* this also skips first '%' */
switch (*fmt) {
case '-':
flags |= LEFT;
goto repeat;
case '+':
flags |= PLUS;
goto repeat;
case ' ':
flags |= SPACE;
goto repeat;
case '#':
flags |= SPECIAL;
goto repeat;
case '0':
flags |= ZEROPAD;
goto repeat;
}
某些字段就不说了,用过printf的应该都知道的,其中的#作用就是方便16进制和8进制的格式化,例如%#x就会被默认加上0x,而%#o就会被默认加上0,具体可以看后面number函数实现就知道了.
找工作太忙了,今天才得有空继续分析^~^(2016.10.17)
接下来就会去获得宽度字段,利用isdigital函数一步实现字符串转整型并使得fmt指针指向后续格式符.如果用*代替,将直接将压入的参数转为整型赋值为宽度字段.并根据正负号置标志位采取相应的对齐方式(默认为右对齐).
1 | /* get field width */ |
再下来就是获取精度了,一般有浮点类型的就得保留多少位的精度.首先得在串中检测到有.字符,之后的处理跟宽度就差不多了.先保存相关的参数然后会传到另外的函数做具体处理的.对于有l,L,h跟在后面的将使得qualifier被置为其ascii码值.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/* get the precision */
precision = -1;
if (*fmt == '.') {
++fmt;
if (isdigit(*fmt))
precision = skip_atoi(&fmt);
else if (*fmt == '*') {
++fmt;
/* it's the next argument */
precision = va_arg(args, int);
}
if (precision < 0)
precision = 0;
}
/* get the conversion qualifier */
qualifier = -1;
if (*fmt == 'h' || *fmt == 'l' || *fmt == 'L') {
qualifier = *fmt;
++fmt;
}
之后就进入最后的格式化匹配了,根据提供的格式化类型对压入的参数进行相应操作.首先会使得base默认为10进制,如果类似%c的话,直接根据左右对齐方式填充空白符,中间以int类型为地址单元取得参数的值直接强制转化为unsigned char类型的字符.为什么呢?详情参考我的另外一篇文章,我们需要知道这个是编译器自己这么压进去的就得这么去接收就行了.对于类似%s,首先取得参数首地址,然后调用安全的strnlen函数获取填充空白的长度.之后逐字符地拷贝,若非右对齐后续还需继续填充空白,if和while没有加{}可能看得不太清楚.建议源代码中的风格严谨一点好.对于%p如果没有字段宽度值则默认为2个指针大小的宽度,并使得flags的ZEROPAD置位.而后直接送往number函数继续处理.%n可是一个很生疏的东西,我猜测这个参数最初的目的是用于调试用的,可以检查本次printf调用在%n之前输出的字符个数,并将这个值赋给调用者传递进来的参数地址处,但是如果使用不当,就可能会造成任意地址读写任意数据的格式化字符串漏洞.
之后的几个参数大都是置位相应标志位而已,后期直接送往number函数处理,需要注意的是之前这几个参数后面完成后用的是continue,意思是直接跳转到最外面的for循环进行下一个字符的匹配,而%xXdiu后面接的是break,表示退出switch,转而进行后面的h,L,l的长类型的处理去了.还要注意在switch case break的结构中,如果case了第一个条件,之后如果没有遇到break,程序的控制流程将忽略后面的case条件,直接执行语句部分,直到遇见结束的break.因为这里已经出现了这种用法(匹配x的时候),所以应该注意一下,某些笔试题也会考察这个知识点.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89/* default base */
base = 10;
switch (*fmt) {
case 'c':
if (!(flags & LEFT))
while (--field_width > 0)
*str++ = ' ';
*str++ = (unsigned char)va_arg(args, int);
while (--field_width > 0)
*str++ = ' ';
continue;
case 's':
s = va_arg(args, char *);
len = strnlen(s, precision);
if (!(flags & LEFT))
while (len < field_width--)
*str++ = ' ';
for (i = 0; i < len; ++i)
*str++ = *s++;
while (len < field_width--)
*str++ = ' ';
continue;
case 'p':
if (field_width == -1) {
field_width = 2 * sizeof(void *);
flags |= ZEROPAD;
}
str = number(str,
(unsigned long)va_arg(args, void *), 16,
field_width, precision, flags);
continue;
case 'n':
if (qualifier == 'l') {
long *ip = va_arg(args, long *);
*ip = (str - buf);
} else {
int *ip = va_arg(args, int *);
*ip = (str - buf);
}
continue;
case '%':
*str++ = '%';
continue;
/* integer number formats - set up the flags and "break" */
case 'o':
base = 8;
break;
case 'x':
flags |= SMALL;
case 'X':
base = 16;
break;
case 'd':
case 'i':
flags |= SIGN;
case 'u':
break;
default:
*str++ = '%';
if (*fmt)
*str++ = *fmt;
else
--fmt;
continue;
}
if (qualifier == 'l')
num = va_arg(args, unsigned long);
else if (qualifier == 'h') {
num = (unsigned short)va_arg(args, int);
if (flags & SIGN)
num = (short)num;
} else if (flags & SIGN)
num = va_arg(args, int);
else
num = va_arg(args, unsigned int);
str = number(str, num, base, field_width, precision, flags);
}
*str = '\0';
return str - buf;
number函数
首先分析一下这个宏定义的作用,如果先看number函数里面用到这个宏居然是放在[]里面的,因此可以猜测作用是用来偏移寻址的.有些人会问,C语言里面可以这样用吗?(答案很明了了,不能用怎么编译通过呢?所以还是需要多看别人写的代码,有些用法不常用的但是如果好用就可以Get到了)编译器编译的时候能够生成合适的代码即可.这个宏的作用是求出n对base余数,并使得n变为商,同时”返回”余数__res.主要用于八进制和十六进制的数值与字符的转换.(不知是否C语言的思想是一切皆为表达式,据说类nix操作系统和shell的核心思想分别是一切皆为文件和一切皆为表达式.)1
2
3
4
5
再来看number函数的实现,首先分析函数的参数以及返回值,作为软件工程师应该要做到文档清晰可理解,各个接口的参数以及返回值的作用解释清楚.static类型的函数表明这个函数仅仅在这个文件作用域可以调用,这样减少了命名冲突问题.`char 返回值表明能够实现链式功能,可对比strcpy函数的实现.再来看参数,第一个str即上层传入的str首地址,表明要对上层传进来的参数空间进行修改.第二个num是对%idp等格式化的栈参数的一个拷贝.第三个base顾名思义就是进制基数了.第四个size即为对齐宽度.第五个为精度,最后一个为标志位字段.
首先定义一个静态的常量数组保存进制转换的字符,便于直接寻址取得相应字符赋值给str.tmp[66]我认为目前来看是有点长,它的作用是暂存num转换之后的数据,num最大为long的最大值,为2^64(64bit),也就是16个F,即16个字符即可,愚以为有点多余~~~.locase探测type字段的SMALL标志,不得不说SMALL标志位也是取得合理,32->第4位置位,使得可以很轻松地或运算实现大写字符->小写字符(ascii码相差32).如果0和-同时置位,gcc编译器会提示warning: ‘0’ flag ignored with ‘-‘ flag in gnu_printf format [-Wformat=],表明会忽略掉0的作用,具体实现也是这样.首先会判断是否有左对齐标志,有的话就用经典的&= ~运算来清除相应标志位,这个在嵌入式开发里面很常见,一般是操作外设寄存器用的.在这里的逻辑是清除补零标志.这里也有一个健壮性的判断,不过number函数仅限于本文件调用,一般的开发者应该不会传入错误的base.字符c也是用来填充的,为0或者空格.接下来就是检测SIGH标志,并根据正负和0填充的需求占据size和置位sign.之后判断16进制和8进制情况,16进制的size减2是由于要填充0x或者0X,8进制只需要填充0即可.之后就开始进制转换成字符了,并根据locase的实际情况对于16进制翻转大小写字符.而对于数字0~9,由于他们的ascii码的第4位已经置位,所以或上1并不影响自身的值,而默认的大写字母第4位没有置位,如果程序员需要转换就可以转换.这个是很巧妙的!!!值得学习的技巧.传进来的precision表示精度,由于这里没有浮点匹配,这里就主要用来截取串的长度.如果ZEROPAD和LEFT都没有置位,就填充空格.然后根据进制继续填充数值.如果不是左对齐,就根据size的剩余大小继续填充c,后面就根据i的情况填充了,直到满足size这个宽度域为0.最后返回str`的首地址.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71static char *number(char *str, long num, int base, int size, int precision,
int type)
{
/* we are called with base 8, 10 or 16, only, thus don't need "G..." */
static const char digits[16] = "0123456789ABCDEF"; /* "GHIJKLMNOPQRSTUVWXYZ"; */
char tmp[66];
char c, sign, locase;
int i;
/* locase = 0 or 0x20. ORing digits or letters with 'locase'
* produces same digits or (maybe lowercased) letters */
locase = (type & SMALL);
if (type & LEFT)
type &= ~ZEROPAD;
if (base < 2 || base > 16)
return NULL;
c = (type & ZEROPAD) ? '0' : ' ';
sign = 0;
if (type & SIGN) {
if (num < 0) {
sign = '-';
num = -num;
size--;
} else if (type & PLUS) {
sign = '+';
size--;
} else if (type & SPACE) {
sign = ' ';
size--;
}
}
if (type & SPECIAL) {
if (base == 16)
size -= 2;
else if (base == 8)
size--;
}
i = 0;
if (num == 0)
tmp[i++] = '0';
else
while (num != 0)
tmp[i++] = (digits[__do_div(num, base)] | locase);
if (i > precision)
precision = i;
size -= precision;
if (!(type & (ZEROPAD + LEFT)))
while (size-- > 0)
*str++ = ' ';
if (sign)
*str++ = sign;
if (type & SPECIAL) {
if (base == 8)
*str++ = '0';
else if (base == 16) {
*str++ = '0';
*str++ = ('X' | locase);
}
}
if (!(type & LEFT))
while (size-- > 0)
*str++ = c;
while (i < precision--)
*str++ = '0';
while (i-- > 0)
*str++ = tmp[i];
while (size-- > 0)
*str++ = ' ';
return str;
}
puts
至于puts的实现应该就不难了,内核中有很多处代码.应该就是简单地逐字节地拷贝到某缓冲区,再由内核的IO调度机制向屏幕或者串口等字符驱动设备文件拷贝输出.一般在嵌入式开发里面串口输出的比较常见.而普通PC的CPU(类似以前8086时代的intel)可能是按照主板等的设计给显存预留出地址空间,只要CPU把数据送往那个地址空间(貌似是0x0B800)显示设备就能够打印出相应的字符.
总结
最起初的printf实现大概就这么多吧,可能内核开发者考虑到某些CPU没有浮点体系就没有把处理浮点类型的情况加进去的,标准的printf实现还是需要参考glibc库的.后期有空继续分析.对了,前面有说到格式化字符串漏洞参考看雪论坛这篇文章,如果没注册看不了的话先戳这里吧