Linux内核0.11完全注释 关于任务睡眠和唤醒的理解
主要理解注释中提到的链表以及缺少几行代码的缘由
何为任务调度?
学过操作系统的筒子们应该有很深刻的理论了,其实说白了就是从现有可运行的任务中选一个最紧急(或者优先级最高)的任务运行,关于如何定义”最紧急”(优先级最高或者说实时进程)才是调度算法去解决的问题,这里先不分析,Linux 0.11内核调度算法也不是很难。
sleep_on()函数
没有源代码的可以参阅这里。这里的代码已经有修复了。Linus原来的代码如下:(中文注释乃赵博士所写~)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// 把当前任务置为不可中断的等待状态,并让睡眠队列指针指向当前任务。
// 只有明确的唤醒时才会返回。该函数提供了进程与中断处理程序之间的同步机制。函数参数P是等待
// 任务队列头指针。指针是含有一个变量地址的变量。这里参数p使用了指针的指针形式'**p',这是因为
// C函数参数只能传值,没有直接的方式让被调用函数改变调用该函数程序中变量的值。但是指针'*p'
// 指向的目标(这里是任务结构)会改变,因此为了能修改调用该函数程序中原来就是指针的变量的值,
// 就需要传递指针'*p'的指针,即'**p'.
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
// 若指针无效,则退出。(指针所指向的对象可以是NULL,但指针本身不应该为0).另外,如果
// 当前任务是任务0,则死机。因为任务0的运行不依赖自己的状态,所以内核代码把任务0置为
// 睡眠状态毫无意义。
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
// 让tmp指向已经在等待队列上的任务(如果有的话),例如inode->i_wait.并且将睡眠队列头的
// 等等指针指向当前任务。这样就把当前任务插入到了*p的等待队列中。然后将当前任务置为
// 不可中断的等待状态,并执行重新调度。
tmp = *p;
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
schedule();
// 只有当这个等待任务被唤醒时,调度程序才又返回到这里,表示本进程已被明确的唤醒(就
// 续态)。既然大家都在等待同样的资源,那么在资源可用时,就有必要唤醒所有等待该该资源
// 的进程。该函数嵌套调用,也会嵌套唤醒所有等待该资源的进程。这里嵌套调用是指一个
// 进程调用了sleep_on()后就会在该函数中被切换掉,控制权呗转移到其他进程中。此时若有
// 进程也需要使用同一资源,那么也会使用同一个等待队列头指针作为参数调用sleep_on()函数,
// 并且也会陷入该函数而不会返回。只有当内核某处代码以队列头指针作为参数wake_up了队列,
// 那么当系统切换去执行头指针所指的进程A时,该进程才会继续执行下面的代码,把队列后一个
// 进程B置位就绪状态(唤醒)。而当轮到B进程执行时,它也才可能继续执行下面的代码。若它
// 后面还有等待的进程C,那它也会把C唤醒等。在这前面还应该添加一行:*p = tmp.
if (tmp) // 若在其前还有存在的等待的任务,则也将其置为就绪状态(唤醒).
tmp->state=0;
}
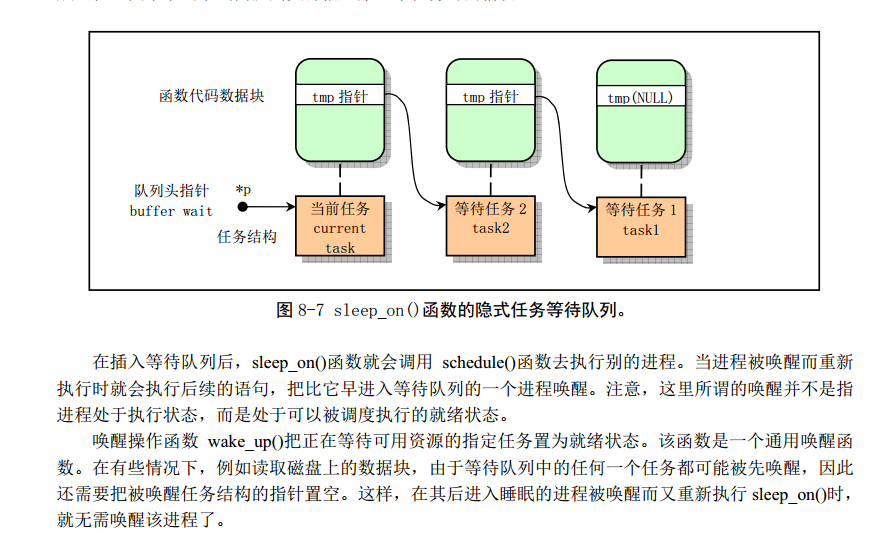
调用此函数的地方一般是资源得不到满足(比如等待缓冲区解锁等场景)而致使自身任务运行到这里时候睡眠。但是等待这个资源的可能不止一个进程,一般管理缓冲的数据结构都会设置一个task_struct结构体指针表示当前正在等待本缓冲区的任务。但数据结构中并没有明显定义链表结构呀?注释里怎么说有呢?其实是”潜移默化”地保存在了各个任务的栈空间中去了。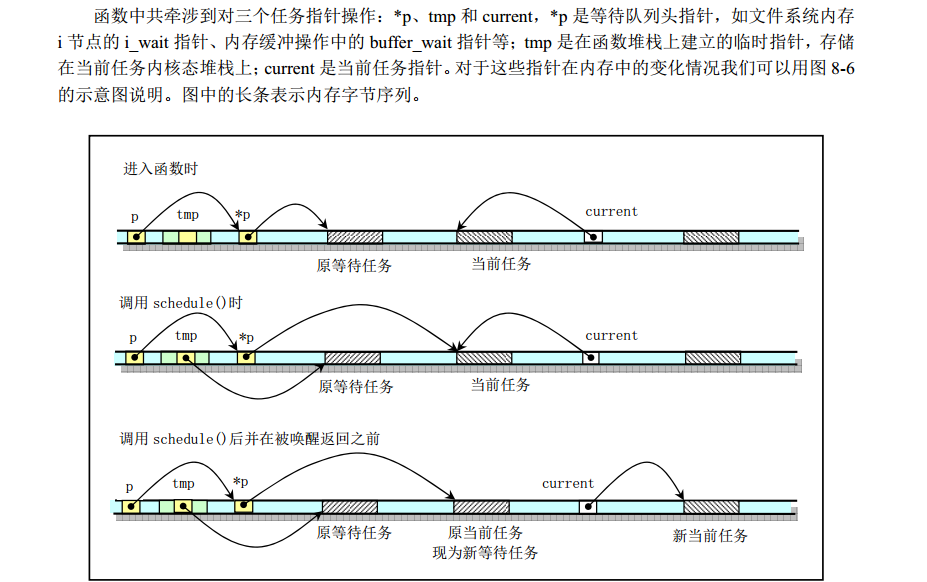
内核代码首先定义一个tmp指针保存已经正在等待本资源的进程(假设叫A),然后将正在等待本资源的进程改变为当前进程(假设叫B),并立即置B进程状态为不可中断地好唤醒,表示只能由wake_up函数来唤醒。之后便进行任务调度,因此B进程会”停止”在任务调度这里,因为如果没有被唤醒(即state置0)是不可能被调度的,调度算法只会选出”状态为0”的进程进行调度运行。假设另外一个进程(假设为C)也需要这个资源,代码也运行到这里(但是它们的进程上下文是不同的),在C进程的栈空间定义一个tmp保存B进程的指针,把C自己的指针赋值到资源等待任务的指针位置,并启用任务调度,同样,C也会”停止”在这里。假设某个时候某个进程手动调用了wake_up函数。此时传递的指针居然是C进程(假设之后没有其他进程需要这个资源了)。好了,C被唤醒了,肯定优先于A和B运行了,貌似不太公平呀,”后来先到”。当调度程序检测到C处于可运行状态的时候并且它的优先级最高,便切换到C运行,而C会从schedule()函数这里继续向后运行,Linus原来的代码仅仅是将tmp任务(这里是B)唤醒,如果在这次之后没有其他任务来竞争这个资源,则也能顺利陆续唤醒(因为B运行完了也会执行到这里,B的tmp保存了A的任务指针…)。但是如果此时有一个任务D也来等待这个资源,D运行到tmp的时候tmp保存的居然还是C的任务指针(因为等待资源任务指针没有被更新)。之后运行完之后继续唤醒C(没啥用,C早就可运行,或者等待其他资源而阻塞,此时唤醒它将会打乱其所在队列…当然一般会有其他策略继续检测)。但是A和B不出意外就永远不能唤醒了。因此赵博士的注释要求增加一行代码*p=tmp,目的是刷新等待缓冲任务指针。(按照栈的意思也得有借有还吧,前面保存了之后也得会送回去呀)至于为什么Linux 0.11版本内核也看出什么大问题可能是由于”竞争”不够激烈,等待真正遇到业务场景复杂的时候弊端就暴露出来了,因此Linux内核版本一直在前进中。
1
2
3
4
5
6
7
8
9// 唤醒*p指向的让任务。*p是任务等待队列头指针。由于新等待任务是插入在等待队列头指针处的,
// 因此唤醒的是最后进入等待队列的任务。
void wake_up(struct task_struct **p)
{
if (p && *p) {
(**p).state=0; // 置为就绪(可运行)状态TASK_RUNNING.
*p=NULL;
}
}
同样的源代码于interruptible_sleep_on函数。大体思路差不多,只不过此状态可被某些信号唤醒,不必要一定调用wake_up函数来置位。如注释所说,因此必须判断是否当前任务是否为等待头指针才能对头指针进行唤醒而自身又置为TASK_INTERRUPTIBLE状态并重新调度。(由于信号对其会产生影响而并不唯一是其他进程唤醒的)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// 将当前任务置为可中断的等待状态,并放入*p指定的等待队列中。
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
// 若指针无效,则退出。(指针所指向的对象可以是NULL,但指针本身不会为0).如果当前任务是
// 任务0,则死机。
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
// 让tmp指向已经在等待队列上的任务(如果有的话),例如inode->i_wait。并且将睡眠队列头的
// 等待指针指向当前任务。这样就把当前任务插入到了*p的等待队列中。然后将当前任务置为可
// 中断的等待状态,并执行重新调度。
tmp=*p;
*p=current;
repeat: current->state = TASK_INTERRUPTIBLE;
schedule();
// 只有当这个等待任务被唤醒时,程序才又会回到这里,标志进程已被明确的唤醒执行。如果等待
// 队列中还有等待任务,并且队列头指针所指向的任务不是当前任务时,则将该等待任务置为可运行
// 的就绪状态,并重新执行调度程序。当指针*p所指向的不是当前任务时,表示在当前任务被被放入
// 队列后,又有新的任务被插入等待队列前部。因此我们先唤醒他们,而让自己仍然等等。等待这些
// 后续进入队列的任务被唤醒执行时来唤醒本任务。于是去执行重新调度。
if (*p && *p != current) {
(**p).state=0;
goto repeat;
}
// 下一句代码有误:应该是 *p = tmp, 让队列头指针指向其余等待任务,否则在当前任务之前插入
// 等待队列的任务均被抹掉了。当然同时也需要删除下面行数中同样的语句
*p=NULL;
if (tmp)
tmp->state=0;
}
总结
CS中学会抽象还是非常重要的,无处不在的数据结构:)