memory_align
关于C/C++中结构体(类)内存对齐问题
各种笔试面试都会涉及的问题,具体的可以查阅相关标准(如C99,C11等)或者翻阅国外知名论坛stackoverflow等寻找相关资料进一步分析,我个人的一些总结如下,如有不对之处,还请诸位不吝赐教.
可参考资料:
维基百科
StackOverflow GCC Structure
GCC文档
1. 首先放出现代PC编译器在实现的时候对于字长的一些典型约定:
32位编译器:
char :1个字节
char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
64位编译器:
char :1个字节
char* (即指针变量): 8个字节
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 8个字节
long long: 8个字节
unsigned long: 8个字节
其中特别需要说明的一点就是指针类型的,任何类型的指针字长(当然包括结构体和类等复合类型)几乎应该只与编译器平台或者说是处理器地址总线长度有关(当然类似8086这种16位的处理器20根地址线的CPU等就另当别论了).关于这一点我认为学过体系结构和组成原理的同学应该会有深刻体会(我们组成原理课有实验就是按照教程实现一个简单的CPU).在C语言中直接使用操作符sizeof(type)就可以得到字节大小,注意这个sizeof不是一个函数而是一个操作符.操作符的话表明结果已经在编译的时候确定了,而函数的话如果编译器不进行优化则等到运行时被调用才会返回值.关于这一点sizeof在有数组的参数中会发生一些奇妙的事情.
2. 变量排放规则(自己的见解)
1. 内置类型对象(如char<1字节>、int<现代PC编译器普遍为4字节>等)的对齐起始地址为其本身大小和编译器默认大小(或用#pragma pack(n)指定的n,一般编译器默认为8字节,可用菜单等命令修改,n一般为1,2,4,8等2的幂值)中最小的一个的整数倍.
2. 整个结构体或者类的大小为它们中的内置类型大小最大的那一个和编译器默认大小(或用#pragma pack (n)指定的n中两者较小的那个的整数倍,而当结构体或者类为定义对象的自定义类型定义时,其对齐方式参照其本身内置的最大的那个的然后再和编译器默认或声明比较中小的那个,意思说由它们中最小的那个代表它们来进行上述操作。
可能听起来很拗口,但是一旦把握了准则在应对这些问题的时候就很轻而易举了.其实主要是两个点,一个是变量放的偏移地址,另一个是复杂类型的总的大小.首先我们要知道为什么编译器需要对变量进行内存对齐?知道内存组织的童鞋可能有些感触,我们的代码运行的时候必须首先从磁盘(或其他非易失性介质)通过外部总线加载到内存中,然后再跳转到相应处运行.基于现有的计算机运行机制不断地进行取指,译码,执行等操作,由于内存本身的半导体的物理特性使得内存并不是一次性有几个G那么多而是通过很小的介质(一般是8位)不断地”串并联”起来的,一般能够保证一个地址能够寻址一个字节的数据,其实是半导体的导通与截止表示的计算机中的”1”和”0”.打个比方,如果地址不是偶数的,要取偶数个的数据的话,CPU在硬件上可能要多花几个时钟周期来进行取数据和整合,才能保证数据不出错.因此很多算法也都是以空间换时间的思想来加快计算.还有就是在嵌入式领域,由于板子或者芯片本身的内存资源非常有限,必须要求嵌入式程序员写出几乎
磕碜的代码才能保证运行流畅等.因此,至少在不怎么缺内存的PC或者Server领域,为了加快计算,还是可以采用编译器进行的优化的.(可能还有其他技术比如缓存啥的我们先不讨论)
3. Win栗子如下:
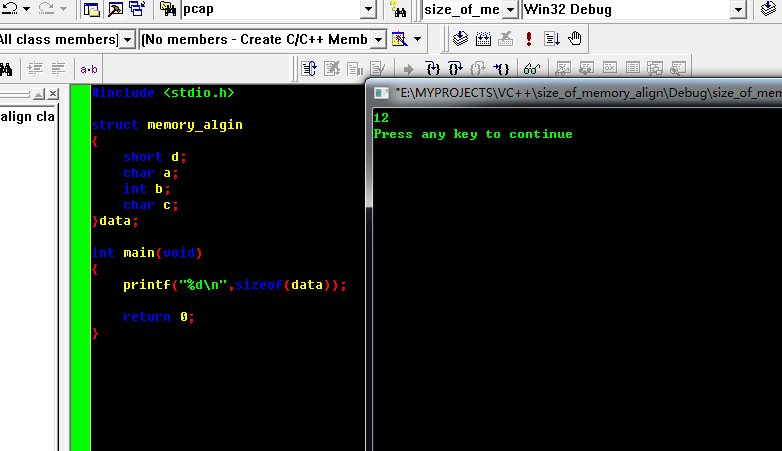
1. 这是以前我用Win的时候VC++ 6.0编译器的效果图
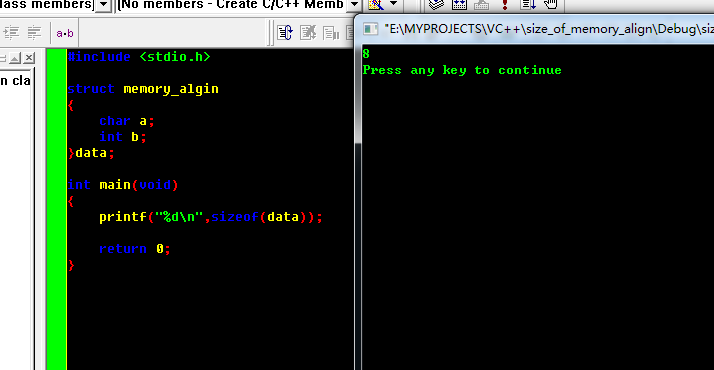
2. 此处说明int类型的b在排位置的时候放到了偏移处为4的倍数,而非数据填充a剩下的
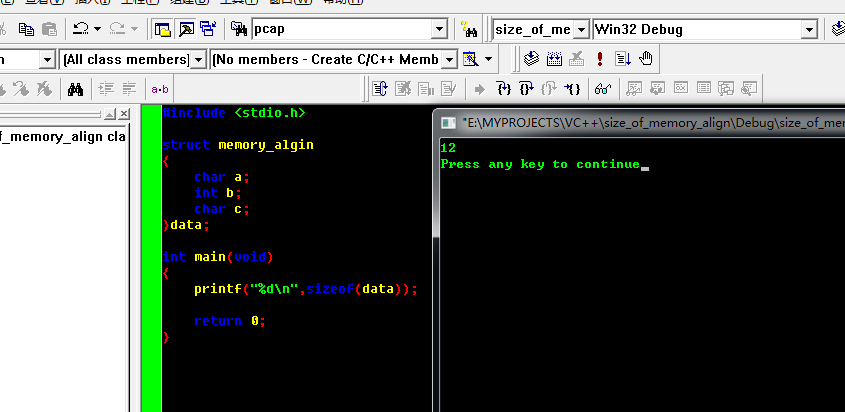
3. 下面这一处说明大小是按照int类型(最大呀)的整数倍来取
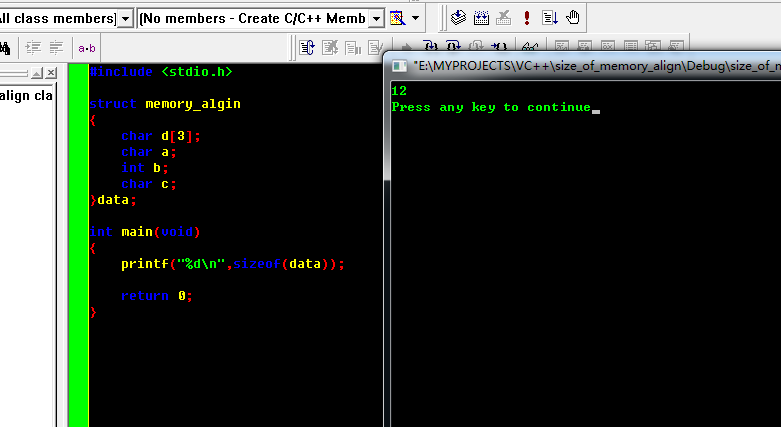
4. 说明当类型为数组的时候,只按照它的类型来对齐而非整个大小
5. 说明第二个元素char类型的可以在任何偏移处安放(因为它是一个字节啊)
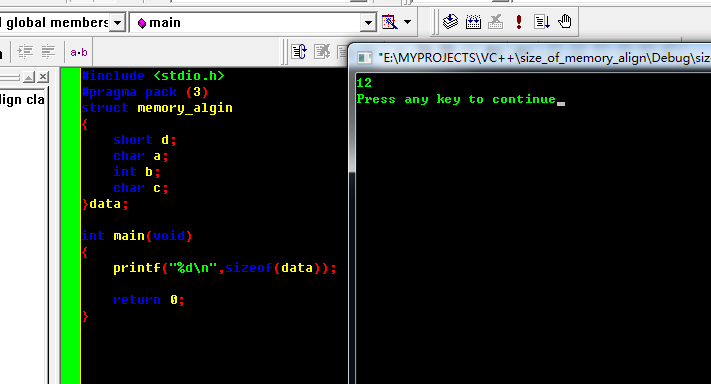
6. 说明#pragma pack (n) n非2的幂的值时候无效
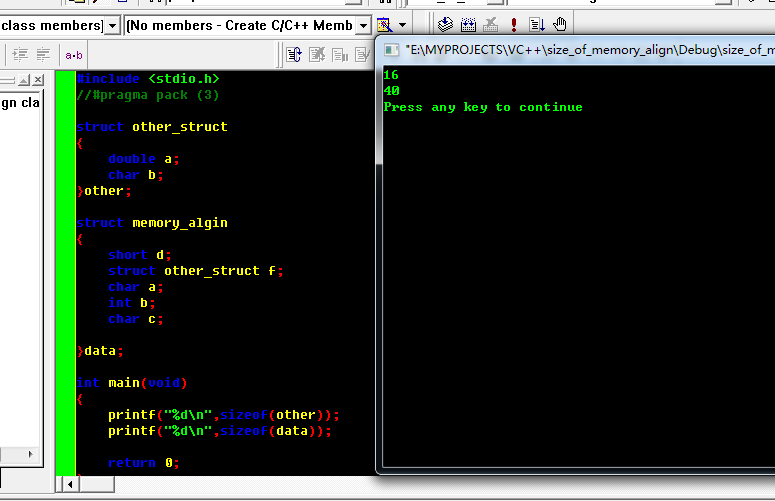
7. 说明结构体作为一个类型在插入时候是以它自己有的最大字节元素来参考放的偏移.然后总的大小是8的倍数
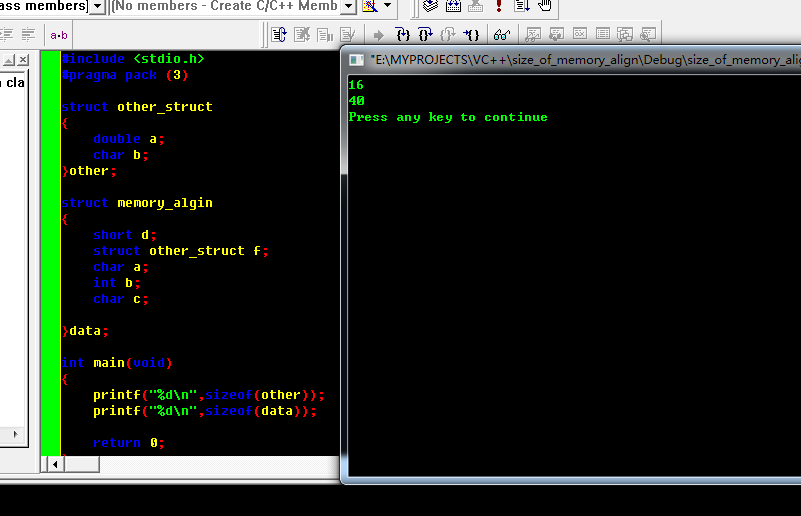
8. 说明pragma pack (3)没作用
4. Linux栗子如下(据说gcc默认是4 bytes的对齐大小):
1. 这是我用ubuntu 16.04 amd64 ssh连接ubuntu 16.04 i386之后gcc版本号:
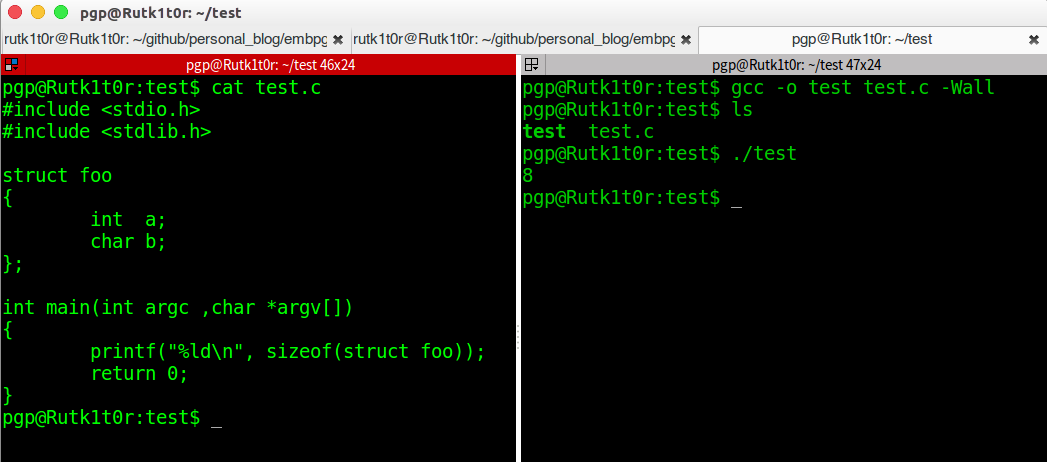
2. 这个应该默认是4字节的对齐,大小和元素中最大的int比还是4字节
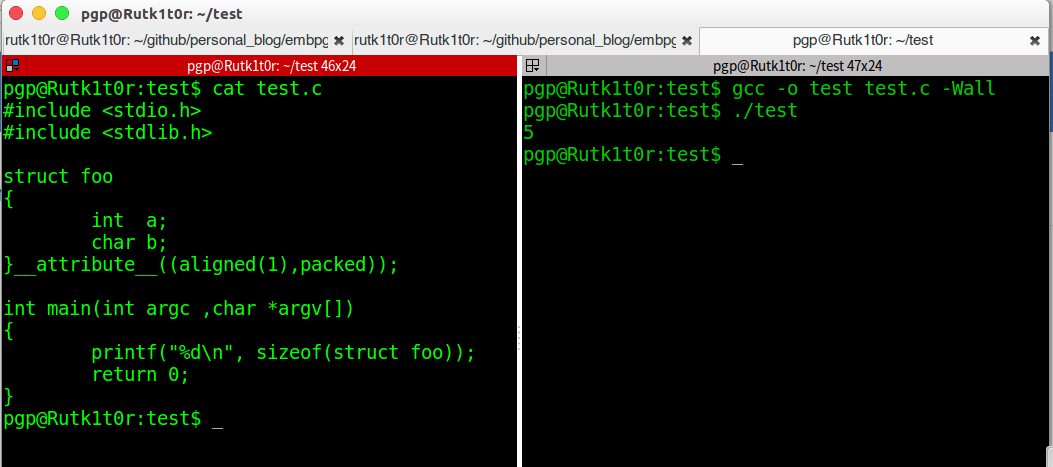
3. 在gcc中加入功能和pragma pack差不多的attribute选项即可要求编译器改变默认对齐大小,当值为1时,几乎没有空间浪费,但是用起来的时候却去坑CPU了…
4. 在这里只是a之后的那一个字节是填充的,short只要是偶数偏移就可以插入咯,int在这里其实也是偶数,只是恰好放在4的倍数偏移处而已,attribute干得好事~
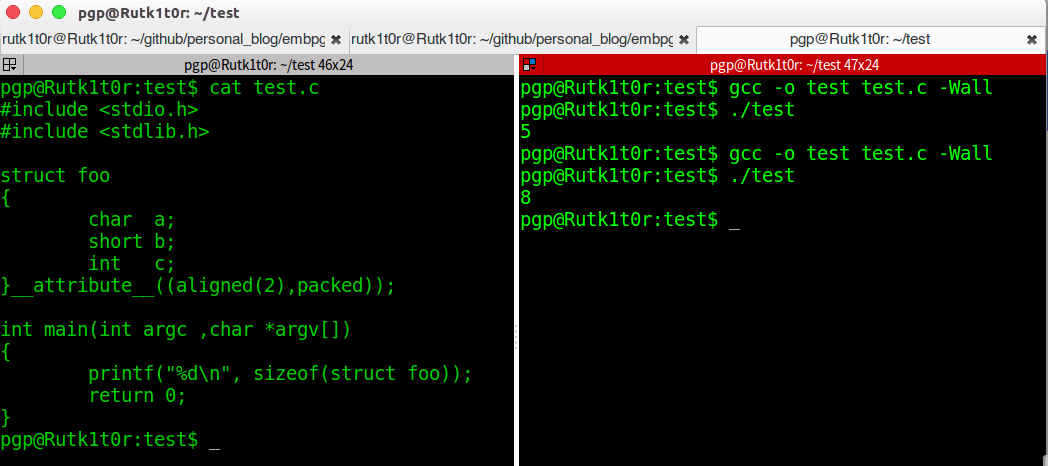
5. 证明了有pack为1的地方必定不留一点空隙~~~
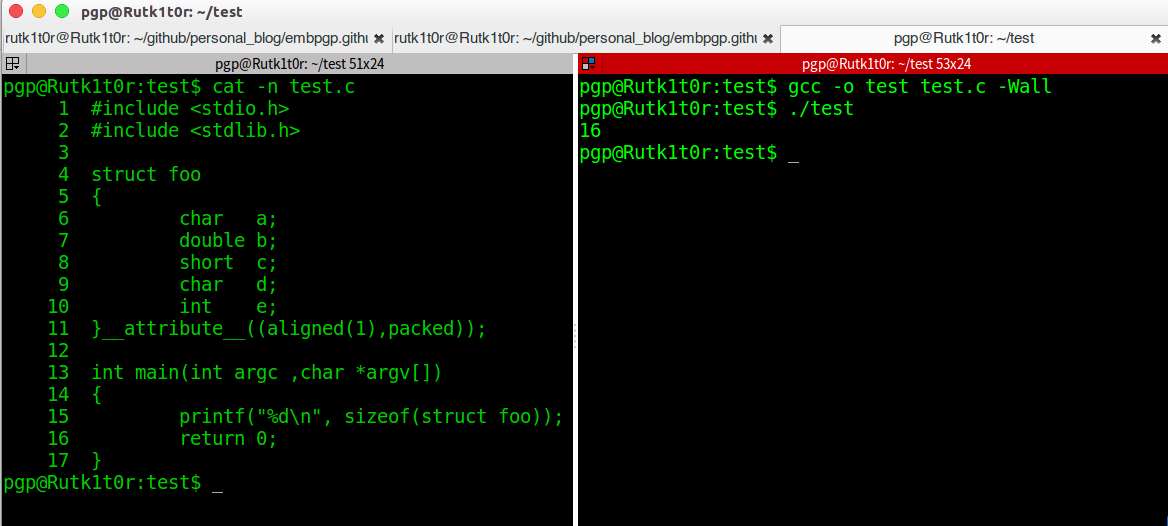
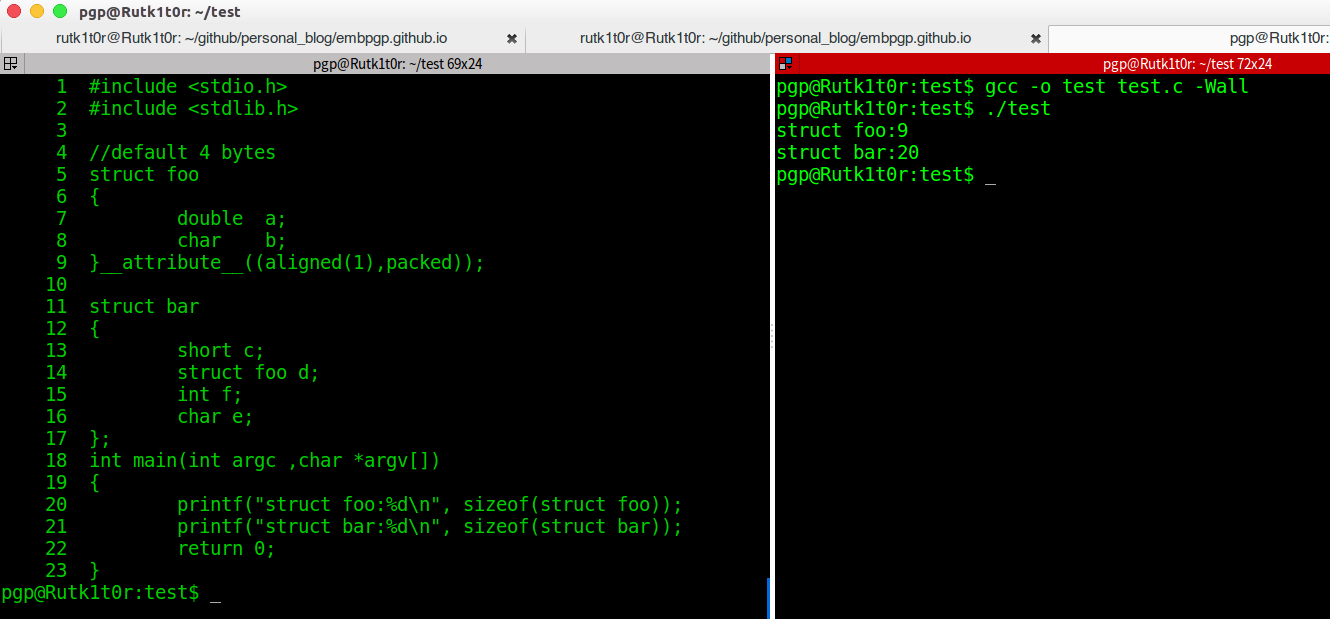
6. 第一个foo结构体虽然double为8字节,但是由于默认为4字节的对齐,所以根据对齐原则取两者中较小的对结构体大小倍数,因此为12字节.第二个结构体bar插入了第一个结构体,因此结构体d放在哪儿呢?应该是它自己作为结构体的时候元素中最大的(这个栗子为double,要是有char 类型数组超过8,不用管,认为是char)和默认的4相比,还是取较小的为偏移处防止,所以short之后空两个就可以插入了.大小也是一样,直接占12字节就是了.后面的参照规则即可得出.
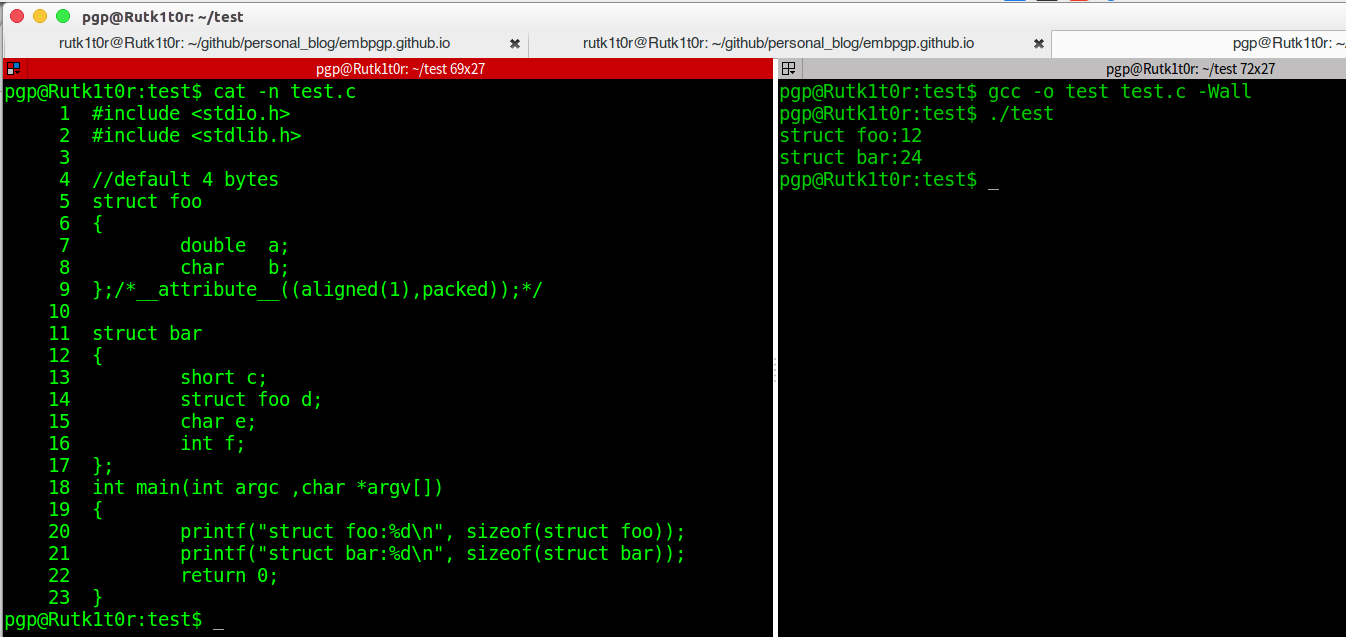
7. 由于第一个结构体声明为1字节的对齐粒度,因此全部都占着吧,但是bar结构体剩余的元素都必须和默认的4进行比较,来放置和占大小.
5. C++中的高级之处
至于C和C++的区别我就不再重复教科书上的内容.只是觉得作为一个developer可能只会关心功能实现,不会管各种机制的内部实现,反正丢给编译器去翻译和安排就是咯,咱又不是研究者.但是一旦出现bug且需要调试器支持的时候,底层的实现就不得不去啃了.编译器也是人开发出来的,当然也少不了出问题,只是现代开发体系为了降低开发难度因此对计算机的封装程度已经快到了
说话编程的地步了.重复造轮子有必要吗?珍爱生命,快用py?
1.C++中的结构体和类的区别?
根据C++的标准它俩的区别应该只是默认的访问权限的不同,其他该有的编译器(比如构造函数,析构函数等)还是会允许程序员实现的.以前在微博上分析过一道题链接.因此,在C++中,为了让编译器能够根据标准对各种权限进行检查并生成程序员想要的代码,还是用class比较好.我们不能单调地看待private声明或者const的成员,认为它是不可能被子类或者其他非正常手段修改的.要知道我们所谓的编程最主要是根据标准和规则对编译器进行交互,让编译器取帮我们做翻译工作,一旦编译器通过,程序被加载到内存中后一切的一切被视为高低电平或者其他二进制信息,到时候让CPU译码之后想怎么干就怎么干~_~(当然这是intel 8086时代,从286开始就开始了保护模式).
2. C++中class的虚函数
C++中的虚函数机制保证了动态绑定,实现了直到程序执行的时候才选择执行哪个代码.一般编译器的实现是在对象空间(类被实例化后)开始的4字节(32位OS)保存一个虚函数表指针,继承了几个类中的虚函数,一般就会产生几个虚函数表指针,再加上数据成员(除去静态成员),这个对象的大小大概就是这么多了.类的方法并不单独属于对象,每一次调用方法的时候必须要传入this指针,其实就是这个对象的首地址.在VC++中一般采用intel 的ecx寄存器作为this指针的载体.例如(obj.func(a, b, c);)在编译器翻译的汇编代码里面等价于(func(&obj, a, b, c);),某些编译器甚至允许这样调用.因为底层的汇编代码一样啊….
先总结这么多吧,其实想真正弄清楚的话还需亲自实现或者读懂一个编译器,不仅仅考虑编译原理里面的词语法分析等,而更要从硬件层面取理解各种软件设计思维模式.毕竟软件是跑在硬件这个载体上面的,各种效率问题要经得起推敲的,为啥选择了GNU/Linux呢?可不仅仅因为是开源免费的原因吧~_~